1. 딥러닝이란
<딥러닝 추천 모델의 필요성>
1) 비선형적 패턴 학습
- 유저 선호의 비선형적인 패턴을 잡아냄으로써, 더욱 복잡한 관계를 학습하여 추천에 활용 가능
2) 다양한 입력 데이터 활용
- 이미지, 텍스트, 오디오,비디오 등 다양한 형태의 입력 데이터를 모델의 입력으로 활용할 수 있음
3) 확장성
- 병렬 처리, 분산 컴퓨팅, GPU 가속 등을 활용해 대규모 데이터를 효율적으로 처리할 수 있음
2. 딥러닝을 위한 학습 기법
2-1. CNN
- 이미지 입력을 받아서 vector representation으로 표현
- 유사한 이미지를 가진 상품을 추천
ConvMF => 텍스트의 임베딩에 CNN을 적용해 특징을 추출, 추천에 활용
2-2. RNN
- LSTM
- 한 명의 유저가 남기는 순차적인 정보(클릭 로그 기록, 구매이력 등)를 기반으로 유저의 선호/행동패턴을 파악해 다음에 클릭/구매할 상품을 추천
- 순차적인 정보를 학습하고 예측하는 데 사용
2-3. Word2Vec
- CBOW / Skip-gram
- 미리 생성한 워드투벡 임베딩을 aggregation해 아이템의 feature로 사용
- 비슷한 상품, 연관 콘텐츠 등을 추천 가능
- 뉴스 추천, 상품명/상품 후기 활용 추천 등
2-4. Attention

- seq2seq : 입력 문장이 길어지면 중요 정보가 손실되는 문제가 발생
- sequence 모델링에서 더 향상된 표현력을 위해 사용
2-5. Transformer
- Encoder 부분에서 설명한 Multi-Head Self-Attention & FFN 부분이 반복
- Encoder-Decoder 부분에서는 Cross Attention이 수행
- 1개의 디코더를 통과한 뒤 값과 인코더 출력 사이의 Attention
- Decoder 부분에서는 Masked Self-Attention이 수행됨으로써 cheating을 방지함
- 최종 Decoder 출력 부분에서 prediction이 수행됨
3. 딥러닝 기반 추천 알고리즘
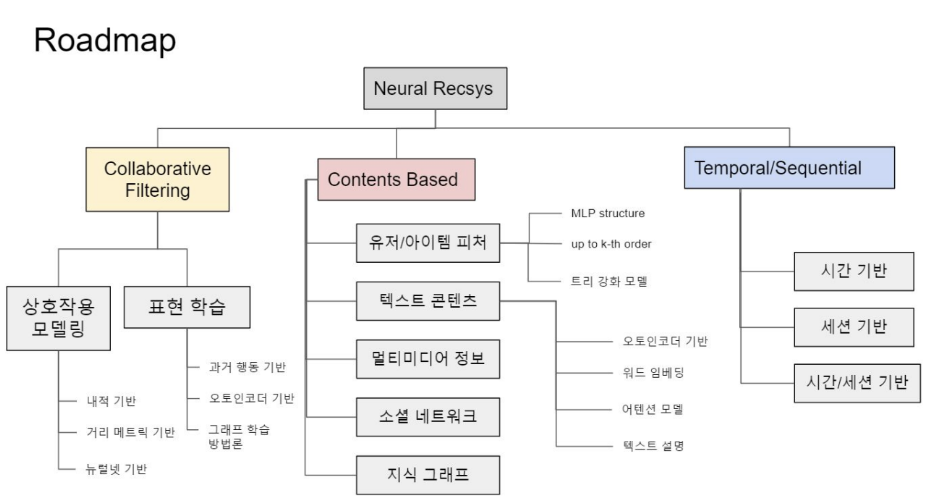
3-1. 딥러닝 추천 시스템의 분류
3-2. CF 기반 딥러닝 모델
- MF의 한계 : implicit matrix가 있을 때 선행모델은 제약을 가짐
- NCF (MLP로 만들어낸 MF 모델)

- collaborative filtering을 뉴럴넷으로 구현
- 입력의 형태는 유저와 아이템에 대한 one-hot 벡터로, 이후에 k 차원으로 맵핑하는 레이어를 통과함
- binary cross-entropy loss (log-loss)가 사용되어 implicit feedback의 확률적인 특성을 반영
- NeuMF (MLP + GMF)

- GMF는 MF의 내적 부분을 element-wise 곱 연산과 비선형 활성함수 (시그모이드)로 대체하여, 기존의 MF를 일반화함
- GMF는 비선형을 잡아내는게 어렵다는 약간의 한계점이 있고,
- 반면에 MLP는 선형 상호작용을 잡아내는 데 효율적이지 않을 수 있다는 단점
- 이 두 모델을 조합하여 서로의 장단점을 상호 보완
- AutoRec
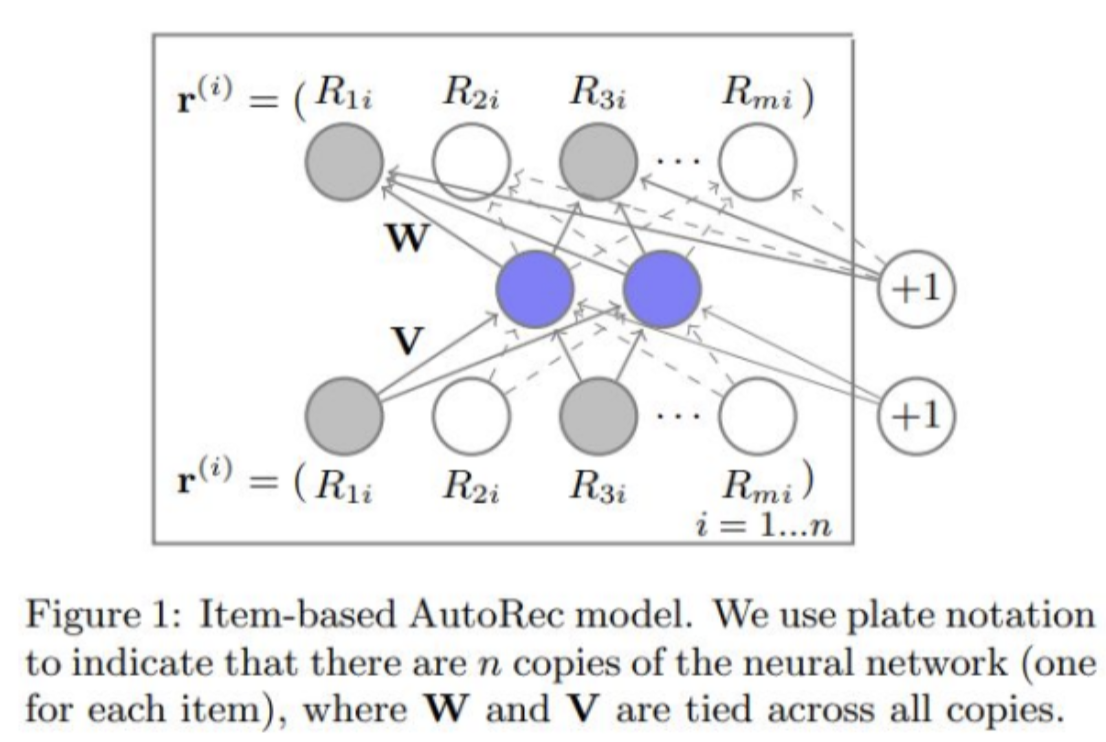
- Auto Encoder의 구조를 통해 Collaborative Filtering을 모델링
- 중간의 Hidden Layer에서 Latent Factor를 학습하고, 이를 복원해 냄으로써 유저의 unrated rating을 추론함
- AutoEncoder와 수식의 차이는, 관찰된 평점만의 기여도를 계산하는 부분
- ConvMF(Convolutional Matrix Factorization)
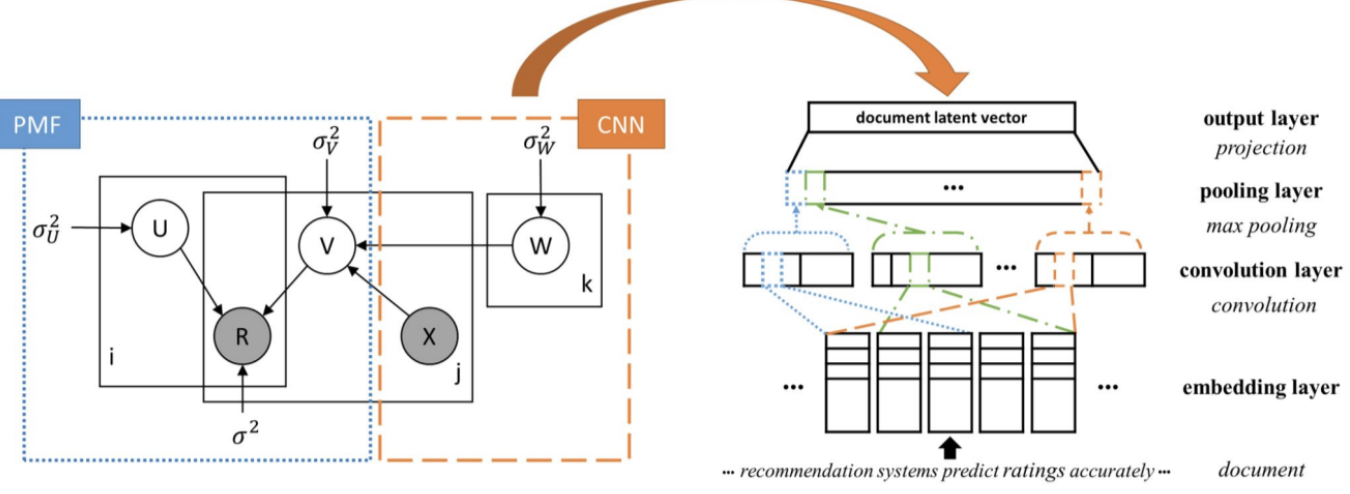
- MF 모델에 CNN 모듈을 결합하여, 텍스트 피처를 반영할 수 있도록 구성한 모델
- 텍스트 임베딩 매트릭스를 컨볼루션하여 문서의 latent vector를 생성, 이를 MF 파트의 최적화 과정에 결합
3-3. FM 기반 딥러닝 모델
- Wide & Deep


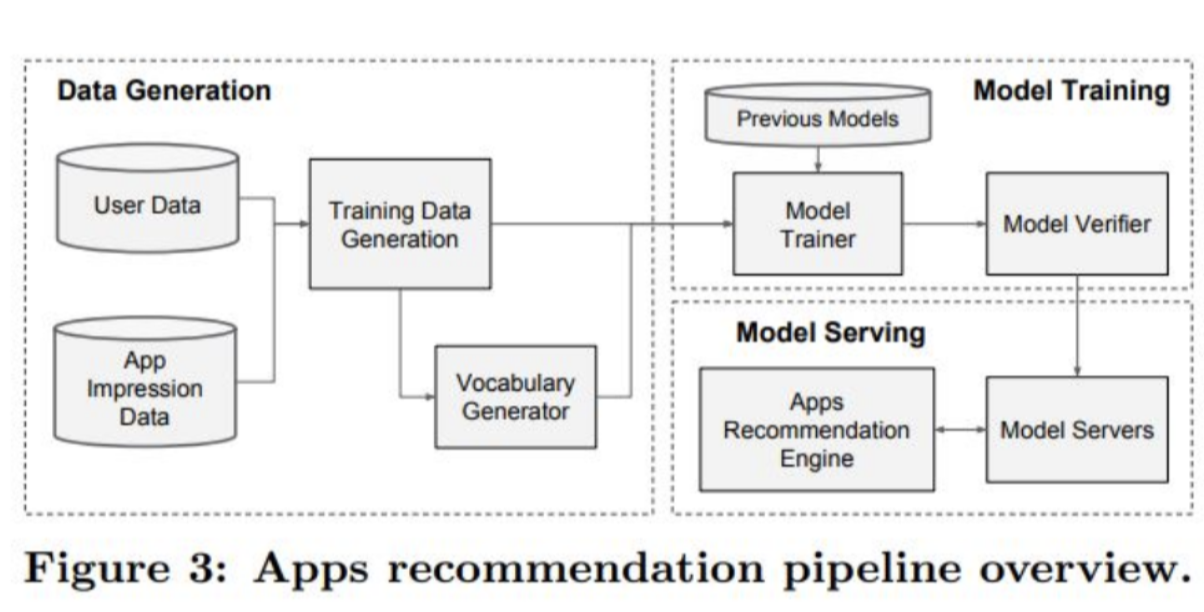
- 데이터 생성: 로그 데이터로부터 학습셋과 vocabulary 생성
- 모델 학습: 생성된 학습 데이터와 정의된 모델로 학습 수행, warm-starting 적용으로 시스템 부하를 최소화
- 모델 서빙: 병렬화와 미니 배치 병렬 처리로 10ms 단위의 속도 내에 처리 가능
- DeepFM (Deep Factorization Machine)

- FM(Factorization Machine) 모델에 뉴럴넷을 적용함으로써, 선형과 비선형 패턴을 모두 잡아낼 수 있도록 고안된 모델
- 하나의 입력으로 통합된 아키텍처를 사용함으로써 효율성과 성능을 모두 확보한 딥러닝 추천 모델의 베이스라인 모델
- NFM (Neural Factorization Machine)

- DeepFM과 마찬가지로, FM 모델에 DNN을 적용한 방법론
- Bi-Interaction Pooling을 적용해 high order feature interaction을 잡아냄
3-4. 시퀀스 기반 추천 모델
- GRU4REC
- GRU(Gated Recurrent Unit)는 LSTM과 비슷한 RNN의 variant로, LSTM에 비해 단순한 구성을 가지고 있음
- LSTM과는 달리 Cell State가 없고, Forget Gate가 없다는 차이점이 존재함
- 성능 상 큰 차이가 없음, LSTM 대비 연산 효율성
- 과거의 기록 sequence가 주어졌을 때, 다음 next item을 예측하는 task
- 시간의 흐름에 따라 동적으로 변화하는 유저의 preference를 포착
- SASRec (Self-Attentive Sequential Recommendation)
- Transformer의 디코더 파트의 구조를 적용한 next-item prediction model
- GRU4REC의 단점을 극복 : GRU는 병렬 처리 불가, 긴 시퀀스 연산 시 시간 소요 증가, Long Term 정보 반영 어려움
- BERT4REC
- Transformer의 인코더 및 디코더 파트의 구조를 활용
- Masked Language Model 구조를 차용, 양방향의 정보를 활용해 학습
출처 : 패스트캠퍼스[30개 프로젝트로 끝내는 추천시스템 구현 초격차 패키지]
'DATA SCIENCE_ 💻' 카테고리의 다른 글
| 05 콜드스타트 문제 해결하기 (0) | 2023.10.14 |
|---|---|
| 04 GNN 기반 추천 알고리즘 (1) | 2023.10.07 |
| 02 머신러닝 기반 추천시스템 (1) | 2023.09.16 |
| 01 고전적 추천시스템 (0) | 2023.09.09 |
| [인프런 수강후기] Python을 이용한 개인화 추천시스템 | 추천알고리즘 | 추천인공지능 (1) | 2023.04.16 |

